- Published on
mongoDB.local seoul 2019에 참가
- Authors

- Name
- Hoehyeon Jung
2019년 09월 06일 진행된 Mongo DB.local Seoul 2019 행사에 참석하고 해당 프레젠테이션을 요약, 정리해보았다.
09:20 - 09:25 인사말
신재성 MongoDB Korea 지사장
- 무중단 서비스 구현 방식에 대한 소개 예정
09:25 - 09:40 데이터를 사용하고, 저장하는데 있어 최적의 데이터베이스 MongoDB
Alan Chhabra, MongoDB 글로벌 파트너 APAC 지역 부사장
개발자를 위한 DB인 MongoDB (Stackoverflow 개발자 설문 조사 1위)
플랫폼 전환(클라우드로의)의 초기 단계에 발맞춰 대응 -> MongoDB Atlas(클라우드 DB)
MongoDB Atlas 소개 : 2016년 AWS 4지역 : 현재 AWS, GCP, Azure 전서버에서 제공
MongoDB에 대한 개발자 요구사항을 만족하고자 함
- 뛰어난 생산성과 신속한 이동성
- 애자일 인프라의 확장성
- 대규모 다형성 데이터 손쉽게 처리
- 원하는 컴퓨팅 환경을 자유롭게 아용
- 점차 높아지는 성능 및 안정성에 대한 기대치 충족
09:40-10:45 MongoDB 신제품 및 신기능 소개
Keynote Session
현대 애플리케이션
- 개발자 생산성
- 인프라 민칩성
- 빅데이터, 다형 테이터
- 성급하고 요구사항 많은 사용자
해당 조건을 모두 수용하는 MongoDB
- 문서 모델: 자연스러운 모델링, 자연스러운 쿼리, 동적 스키마
- 분산 시스템: 높은 가용성, 확장성, 워크로드 분리, 지리적-배치
- 트랜잭션
- Replica Set Transaction : RDB ACID유사(익숙), 대화형, 고성능, 분산 트랜잭션은 내부에서 알아서 처리
- Distributed Transaction : 대화형, ACID, 커밋전 기록 열람 가능, ...
현대 운영 : 가용성, 모니터링 & 경보, 백업, 셀프 서비스, APIs
- MongoDB Ops Manager : On-premise tools
- MongoDb Atlas: Public Cloud DB
Ops Manager features
- 백업: 적시 복원, 쿼리 가능한 스냅샷, 아키텍처 간소화
- Kubernetes 배포와 함께 작동
Atlas features
- 클라이언트측 필드 수준 암호화 : 개발자에게 투명, 유연한 동적 키 선택..
Live Feature showing : Full text search Atlas 에서 제공하는 인텍스 수행을 통해 GUI로 설정하여 어플리케이션에 적용 가능 : MongoDB Charts GA(generally Available) GUI로 조절 가능, 보안/비보안 설정 가능, 사용자 구별 필터 등을 설정 가능 : Data Lake AWS S3에 json, gson, csv, tsv 등 데이터 등을 연결해서 쿼리할 수 있는 기능
- Realm (모바일 DB)와의 통합
11:00 - 11:30 분산 트랜잭션 - 큰힘에는 큰 책임이 따른다
ACID, Transaction
- 자체적인 코드 구현보다 MongoDB 트랜잭션의 2배 이상의 성능 보유
sharding된 DB에서 성능을 내기 위해서는
- 데이터를 한곳에 모아서(co-location)
- 하나의 shard에만 write 하기
Read CONCERN = READ ISOLATION
Options: Local, Majority, SNAPSHOT, LINEARIZABLE(new features)
Locking
Locking 획득을 위한 시간 간격을 exponential back off(지수적 증가) read -> Locking을 확득하지 않음
11:30 - 12:00 MongoDB in Banksalad
뱅크샐러드에서 MongoDB 사용 배경 이전 2번의 실패.. 세번째 도전 (2017)
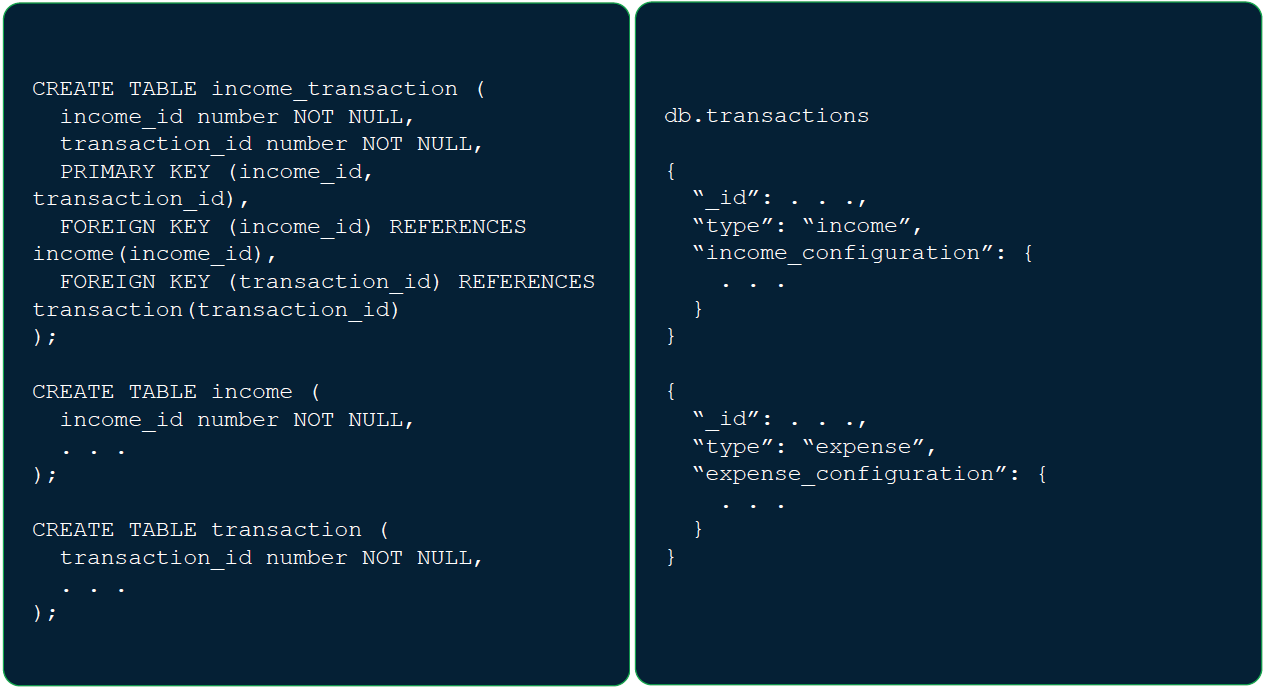
고민 1. 표현력 (RDB) 가계부 데이터 예시 - 내역
- 이체 (계좌 간 돈이동)
- 지출 (계좌에서 돈이 인출)
- 수입 (계좌로 돈이 입금) 내역 transaction 데이터가 내부적으로 지출, 수입, 이체(계좌 간 돈 이동)로 나뉘고 각각 형태가 상이한 경우가 빈번
 ;
;
RDB -> NoSQL(MongoDB)
- 이전 2번('15, '16)의 실패 이유 분석 사용자를 잘 아는가? -> 사용자를 어떻게 하면 알수 있는가?
개인이 학습한다고 해서 제품이나 서비스를 고객에게 전달하는 방식에서 변화가 있는 것도 아니다.
| 전통적인 조직 | 학습하는 조직 | |
|---|---|---|
| 확실성/예측성 | 높음 | 낮음 |
| 목표 달성 방안 | 명확 | 불투명 |
| 일하는 방식 | 분업 | 협업 |
| 활동 | 계획,역할,예산,일정 | 실험,측정,방향,투자 |
개발 전략
"어떻게 하면 방향을 조절할 수 있는가?" "이 방향이 잘못된 방향이라면 어떻게 하면 이를 더 빨리 알 수 있을까?"
고민 2. 생산성
"우리가 지금 하는 일이 우리의 실헙(학습)을 3달 미룰 만큼 가치있는 일인가?"
고민 2. 생산성(개발)
- Python 환경 활용성
- 해당 기술 생태계의 성장 가능성
- 개발 시 문제 해결에 도움되는 자료와 커뮤니티의 성숙도
사용자를 이해하지 못한 상태에서 이후 변경에 있어서 용이성이 있는 DB를 찾아보자
고민 2. 생산성(운영)
- 회사 내 DB 전문가 부재
- 앞으로도 채용 확률 낮음
- 내부 인원을 DB 전문가로 키울수도 없음
- DB 선택 기준
- DB Instatnce 관리
- 확장에 대한 대응(scale-up, scale-out)
- 문제 해결에 대한 도움
- 현재 운영 인프라 지원 여부(AWS)
MongoDB가 사실상 유일한 후보
Backsalad에서 사용 예정인 mongoDB
- MongoDB Change Streams
- MongoDB Stitch (마이크로서비스 간의 정합성)
- MongoDB Atlas Data Lake
요약
우리가 다루는 문제
- 불확실성이 큰 문제 => 풍부한 표현력(의 데이터) -> document 타입
- 비즈니스 가설의 빠른 검증이 필요 => 개발 및 운영의 생산성
13:00 - 13:30 MongoDB Atlas Data Lake 기술 심층 분석
Atlas Data Lake의 필요성
- 기업들의 엄청난 데이터 보유
- 클라우드 스토리지에 장기 데이터를 보관하는데 비용효과적
- 운영이 까다로움
기술 분석?
- MongoDB의 와이어 프로토콜 사용
- MongoDB Query Language(MQL) 지원
- MongoDB 보안 모델
- 고객 데이터 보안
- 확장 가능한 처리
- 데이터 형식 (Apache avro, ..., bson, json, csv, tsv, ...)
Data Lake 생성 방법
- Atlas 클러스터
- AWS에서 한 개 이상의 S3 버킷
- AWS CLI로 접속 가능한 IAM role 필요
MQL -> 분산 MQL
- 쿼리 구문 분석
- 병렬 방식 처리
- 워크로드 분산
링크 참고: data-lake-configuration Docs
13:30-14:00 사용자 경험 및 MongoDB Support Portal 활용[Line]
Agenda
- MongoDB In Line Corp
- Surpport Portal 활용
MongoDB in Line Corp
[사진1-사용 예]
[사진2-]
[사진3-구성]
Support Portal 활용
계약 전: jira.mongodb.org 계약 후: support.mongodb.com
PSA -> PSS
[사진 정리하기]
14:00-14:45 Aggregation Pipeline Power++: MongoDB 4.2 파이프 라인 쿼리, 업데이트 및 구체화된 뷰 소개
Aggregation Pipeline 소개
Stream Stage <-> Blocking Stage 쿼리 튜닝 방식 차이
Update 에서 집계 파이프라인 사용
update 구문에서 []로 aggregation pipeline 적용 가능 (mongoDB 4.2 이상)
새로운 $merge 스테이지
$merge 적용 예시
참고) Materialized View: View를 통해 직접 콜렉션에 접속하기보다 업데이트 된거만 자동으로 맞춰주는 view
15:00-15:40 MongoDB Charts로 데이터 사파리를 시작하세요
MongoDB Atlas Charts Demonstration...
15:40-16:15 속도의, 속도에 의한, 속도를 위한 몽고DB(네이버 컨텐츠 검색과 몽고DB)[Naver]
1. 네이버 검색에서 몽고 DB
1.1 네이버 컨텐츠 검색
: 인물, 영화, 방송, 날씨, 스포츠등 다양한 주제의 검색 쿼리 대응
1.2 네이버 컨텐츠검색과 몽고 DB
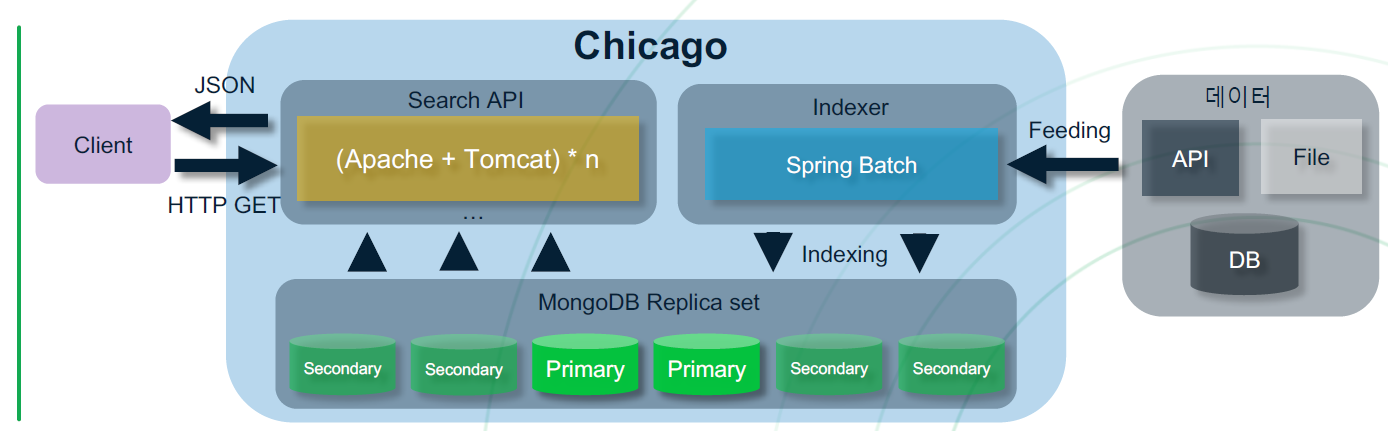
2. Why mongoDB
FAST + SCALABLE + HIGHLY AVAILABLE = MongoDB
- 통합검색 1초 룰, 평균 응답속도 10ms 미만.
- 일 평균 4~5억건 이상 서버 호출, 초당 6천건 수준, 몽고 DB는 초당 만건 이상.
3. 몽고DB 속도 올리기 - Index
3.1 MongoDB Index 이해하기
- 컬렉션당 최대 64개 인덱스만 생성 가능.
- 너무 많은 인덱스를 추가하면, side effects 발생
- Frequent Swap.
- Write performance 감소.
3-2 Index prefix를 사용하자
Index prefixes are the beginning subsets of index fields.
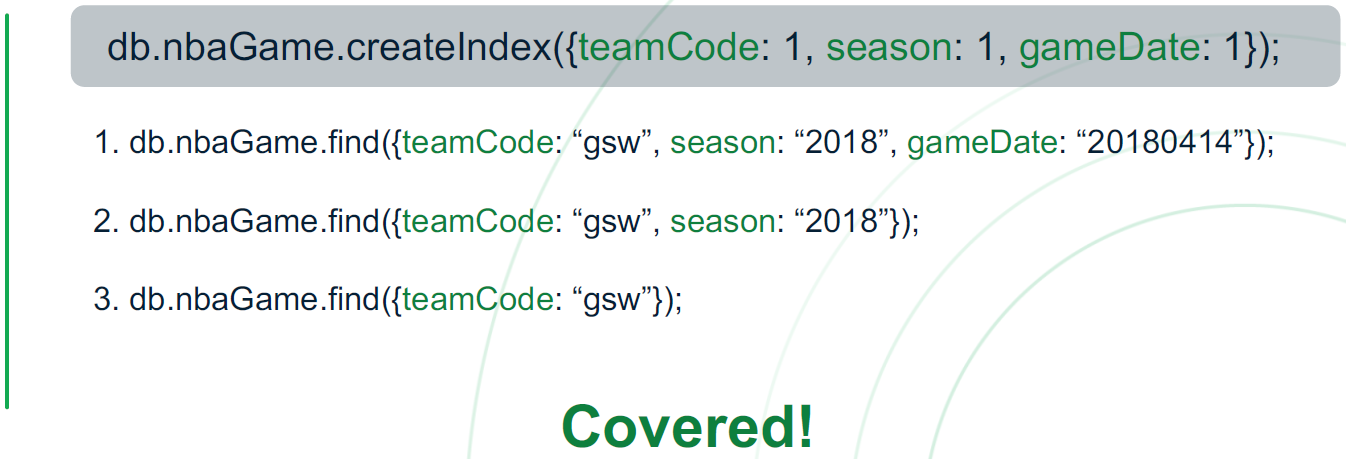
인덱스 생성 시, 적용된 순서 및 그 하위의 순서로 검색 시 인덱스를 통한 검색

인덱스가 적용되지 않는 경우는 위와 같음
3-3 멀티 소팅

4. 몽고DB 속도 올리기 - ^Index
4-1 하나의 컬렉션을 여러 컬렉션으로 나누자
- 하나의 컬렉션이 너무 많은 문서를 가질 경우, 인덱스 사이즈가 증가하고 인덱스 필드의 cardinality가 낮아질 가능성이 높음
- 이는 lookup performance에 악영향을 미치고 slow query 유발
- 너무 많은 문서가 있는 컬렉션은 반드시 나눠 query processor가 중복되는 인덱스 key를 look up하는 것을 방지해야 함
4-2 쓰레드를 이용해 대량의 Document를 upsert
- 여러 개의 thread에서 Bulk Operation으로 많은 document를 한번에 write
- document transaction과 a relation은 미지원
- Writing time을 획기적으로 개선 가능
속도가 중요하고 transaction이 필요없으면 thread 나눠서 write하는거도 방법
4-3 MongoDB 4.0으로 업그레이드
- 몽고DB 4.0 이전에는 non-blocking secondary read 기능이 없었음
- Write가 primary에 반영되고 secondary들에 다 전달될 떄까지 secondary는 read를 block해서 데이터가 잘못된 순서로 read되는 것을 방지
- 주기적으로 높은 global lock acquire count가 생기고 read 성능 저하
- non-blocking secondary read
- 몽고DB 4.0부터 data timestamp와 consistent snapshot을 이용해 이 이슈를 해결
5. 미운 Index
5-1 Slow Queries...
네이버의 API 호출 속도 기준인 10ms에 못미치는 쿼리 발생
5-2 Explain 결과

참고) key examined > 10000 이면 100ms이상 걸림
5-3 이게 최선일까?
전체 9만 개의 문서에서 100여개의 검색 결과를 찾기 위해 수 만개의 문서를 탐색. 사전에 정의한 인덱스에 따라 탐색하면 문제가 없어야 함
5-4 인공지능 보단 인간지능
각 쿼리별 새로 정의한 인덱스 생성
예상 시나리오: 새로운 Index를 타면 해당 인덱스를 타서 검색 시간이 개선될 것
실제: 해당 인덱스를 타지 않음!
hint를 이용하여 강제로 인덱스 태우기
강제로 인덱스를 태우니 검색 시간 단축
5-5 Index가 미운짓을 하는 이유
왜 자꾸 엉뚱한 인덱스를 타는 걸까? 의문
- 몽고 DB가 최선의 쿼리 플랜을 찾는 방법은?
답은 Query Planner에 있음
- 이전에 실행한 쿼리 플랜을 캐싱
- 캐싱된 쿼리 플랜이 없을 경우, 가능한 모든 쿼리 플랜들을 조회하여 첫 **batch(101개)**를 가장 좋은 성능으로 가져오는 플랜을 캐싱
- 성능이 너무 안좋아지면 위 작업 반복
- 캐싱의 사용 조건은 같은 Query Shape의 경우
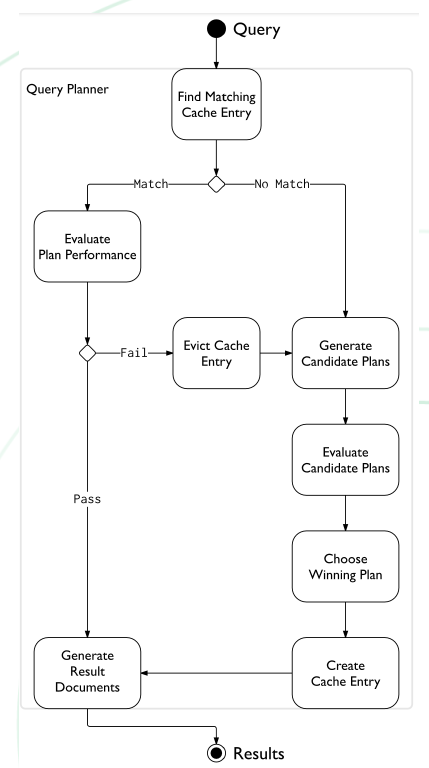
Query Planner가 count() 쿼리의 Query Shape로 첫번째 batch를 가져오는 성능을 테스트를 했을 때 엉뚱한 인덱스가 제일 좋은 성능을 보인 것이 문제
- 만일 동점의 경우, in-memory sort를 하지 않아도 되는 쿼리 플랜 선택 (몽고DB는 32MB가 넘는 결과값을에 대해선 in-memory sort가 불가능하므로)
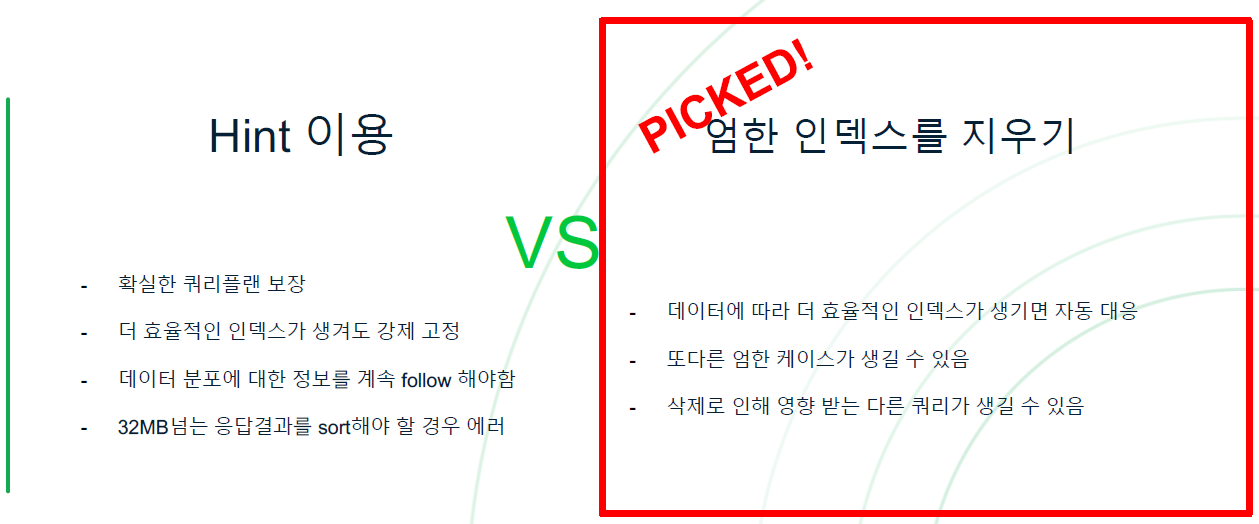
16:15-16:50 MongoDB Data 모델에 대한 전체적인 방법론
Goals of the presentation
- 문서 vs 테이블
- 방법론
- 스키마 패턴
문서 (document)
- 다형성 (polymorphism): 문서마다 다른 필드가 포함될 수 있음
- 배열 (Array): 일대다 표현, 별도의 인덱싱쿼리
- 서브문서
- json
방법론
1. 워크로드 분석(주요 factor 사이즈 파악, 정량화 등 필요)
- 시나리오 구성
- 수량화 및 검증 작업
- Write 작업 세부 사항
- Read 작업 세부 사항 -> 분석전용 노드(Hidden Secondary)
2. 관계모델에 대한 분석
3. 스키마 패턴 적용
- Attribute 패턴
- Extended Reference 패턴
- Subset 패턴 (자주 사용되는 부분과 덜 사용되는 부분을 나눔)
- Computed(Read panout, write panout) 패턴 (ex. 계산 부분을 미리 저장하여 해당 부분만 읽어 오기)
- Bucket 패턴(RDB를 JSON으로 변경한 패턴의 경우 자주 발생, 특정 주제에 대해서 묶어서 bucket으로 묶어서 관리하면 Index) Computed 패턴과 섞여서 적용될 수 있음 , Attribute 같은 모델, Document size Control 용이 등 장점
- Schema Versioning 패턴(요구사항 변경에 용이하게 버젼을 입력하여 관리)
- 기타 등등...