- Published on
바닥부터 다시 쌓은 서비스 - MSA 아키텍처 도입기
- Authors

- Name
- Hoehyeon Jung
Intro
MSA(Microservice Architecture)는 기존의 모놀리식 아키텍처에서 발생하는 문제점을 해결하기 위해 등장한 아키텍처입니다. 이런 MSA의 도입 배경과 도입 과정에서 발생한 문제점과 이를 해결하기 위한 방법에 대해 알아보겠습니다.
기존 아키텍처의 문제점
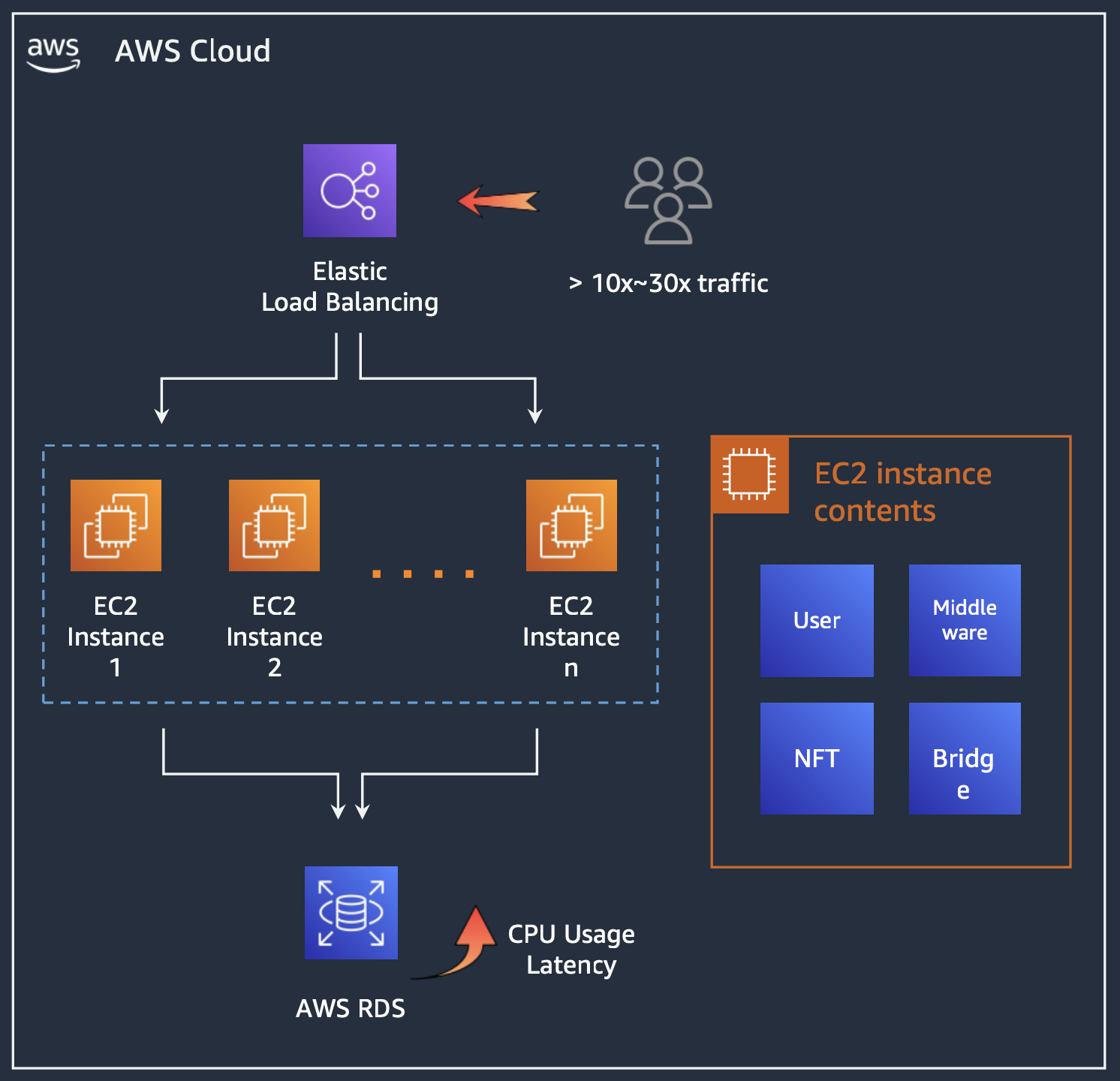
기존의 모놀리식 아키텍처는 하나의 서비스에 모든 기능이 포함되어 있습니다. 따라서 트래픽이 증가하게 되면 DB 부하가 증가하고 해당 DB를 사용하는 전체 서비스들의 응답 속도가 느려지는 문제점이 있었습니다.
MSA 아키텍처의 도입 배경
트래픽이 높을 것으로 예상되는 AA급 게임 서비스와 플랫폼이 연동되어야 했습니다. 이를 해결하기 위해 단순하게 인스턴스나 DB의 사양을 늘리기보다 기존의 모놀리식 아키텍처에서 서비스를 분리하여 서비스 간의 통신을 위한 API를 개발하였습니다.
MSA 아키텍처 구축하기
이제 실제적으로 MSA 아키텍처를 도입하기 위해 기본 전제를 설정하겠습니다. 기존에도 AWS를 사용하고 있었기 때문에 이를 기반으로 MSA 아키텍처를 구축하겠습니다. 또한 별도의 인프라 구축 인원이 없기 때문에 AWS Managed Service를 사용하게 되었습니다.
1. AWS Lambda 구성 (API)
기존에 EC2에서 동작하던 API 서버를 AWS Lambda로 변경하였습니다. AWS Lambda는 서버리스 아키텍처로써 서버를 관리할 필요가 없기 때문에 트래픽 증감에 따른 인프라 관리 부담이 없는 팀에서 활용하기 최적이란 결론에 이르러 활용하게 되었습니다. 또한 AWS Lambda 함수들의 배포를 용이하게 하기 위해 Serverless Framework를 사용하였습니다.
Serverless Framework를 통해 모든 AWS Lambda 함수들은 API Gateway를 통해 외부로 노출되게 됩니다. API Gateway는 AWS Lambda 함수들의 엔드포인트를 관리하고 트래픽을 분산시켜주는 역할을 합니다. AWS Lambda에서 직접 엔드포인트를 관리할 수도 있지만, API Gateway를 사용하면 트래픽 제한과 같은 기능을 사용할 수 있기 때문에 API Gateway를 사용하게 되었습니다. Token Bucket 알고리즘을 사용하여 트래픽을 제한하고, 트래픽이 허용량을 초과할 경우 429 Too Many Requests 에러를 반환하게 됩니다.
리전 당 동시성 할당량에 따라 1000~30000 동시성을 가질 수 있고 단일 리전에서 서비스가 구성되어 있었기 때문에 이를 기준으로 계산하려 합니다. 요청 당 실행 함수 횟수를 설명하기 위해 Public API는 다음과 같은 구조로 되어 있습니다.
Public API(AWS Lambda) <-> Internal API(AWS Lambda) <-> NoSQL(MongoDB)
Middleware API(AWS Lambda) <-> [Internal API(AWS Lambda) <-> NoSQL(MongoDB)] <-> External Service(Blockchain, Game, Payment, etc..)
Public API 요청의 응답 시간이 평균적으로 250ms라고 가정합시다. 서버가 싱가포르에 위치하고 있었기 때문에 이를 기준으로 계산하였습니다. 이 중에 ap-southeast-1(싱가포르) 리전의 경우 AWS의 latency를 측정할 경우 평균 90ms정도가 측정되었습니다. 따라서 250ms의 응답 시간 중 90ms는 latency로써 latency를 제외한 160ms를 함수 실행 시간으로 계산하였습니다. 기업 사용자들만 이용 가능한 Middleware API의 경우 외부 서비스를 호출하는 API가 존재하고 해당 서비스가 국내에 있는 경우가 많아 평균적으로 2배인 500ms의 응답 시간이 소요되었습니다.
또한 Lambda와 연동된 API Gateway의 경우 REST API 설정의 경우 1초당 5000개의 요청을 처리할 수 있으며 bust 요청 시 10000개의 요청을 처리할 수 있습니다.
RPS 계산식은 다음과 같습니다.
RPS = DAU * Daily Personal Average Request / 86400
DAU는 일일 사용자 수를 의미하며, Daily Personal Average Request는 일일 사용자 당 평균 요청 횟수를 의미합니다. DAU는 1만명으로 가정하고 Daily Personal Average Request는 20회로 가정하였습니다. 이를 통해 RPS는 다음과 같이 계산됩니다.
RPS = 10000 * 20 / 86400 = 2.3148 RPS
이는 API Gateway의 기본 제한인 5000 RPS보다 낮기 때문에 API Gateway 요청으로 전부 처리할 수 있게 됩니다.
참고. API Gateway 할당량
동시성 = (초당 요청 횟수) * (요청 수행 기간)
Lambda의 동시성은 위의 공식을 통해 계산할 수 있습니다. 만일 서비스가 기하급수적으로 확장되서 1초에 100개의 요청을 처리하게 되었다면 다음과 같이 계산할 수 있습니다.
동시성 = 100 requests/second * 0.160 second = 16 concurrent requests
즉 하나의 API(Lambda 함수)가 16개의 요청을 동시성을 소모하게 됩니다. 마이크로서비스로 수행되는 만큼, 수십개의 Lambda가 동시에 호출되는 경우가 발생할 수 있게 됩니다. 기본적으로는 AWS Lambda는 리전 당 1000개의 함수를 동시에 실행할 수 있습니다. 하지만 마이크로서비스인 만큼, SQS나 기타 서비스에도 AWS Lambda가 활용되면서 동시성 할당량이 부족할 수 있게 됩니다. 따라서 이 부분을 AWS Solution Architect 팀과 협의하여 목표 활성 인원에 맞춰 필요한만큼 동시성을 사전에 증가시켰습니다.
2. AWS CloudFormation 구성 (CI/CD)
기존에는 AWS CodeDeploy를 사용하여 배포를 진행하였습니다. 하지만 AWS CodeDeploy는 코드를 배포하기엔 좋았지만 이외의 인프라 구성에 관련된 부분은 직접 설정해야 하는 단점이 있었습니다. 인프라까지 통합적으로 관리하면서 AWS Lambda 함수들의 버전 관리를 위해서 AWS CloudFormation을 활용하게 되었습니다.
Github Actions와의 연동을 통해서 코드 배포와 동시에 빌드가 진행되고 AWS에 배포되는 CI/CD를 구축하였습니다. 배포용 AWS IAM을 생성하고 Github Secrets에 등록하여 Github Actions에서 사용하도록 하였습니다. 또한, 추가적으로 Slack 알림을 위한 Incoming Webhook을 생성하여 Slack에 배포 알림을 받을 수 있도록 하였습니다.
3. MongoDB Atlas 구성 (NoSQL)
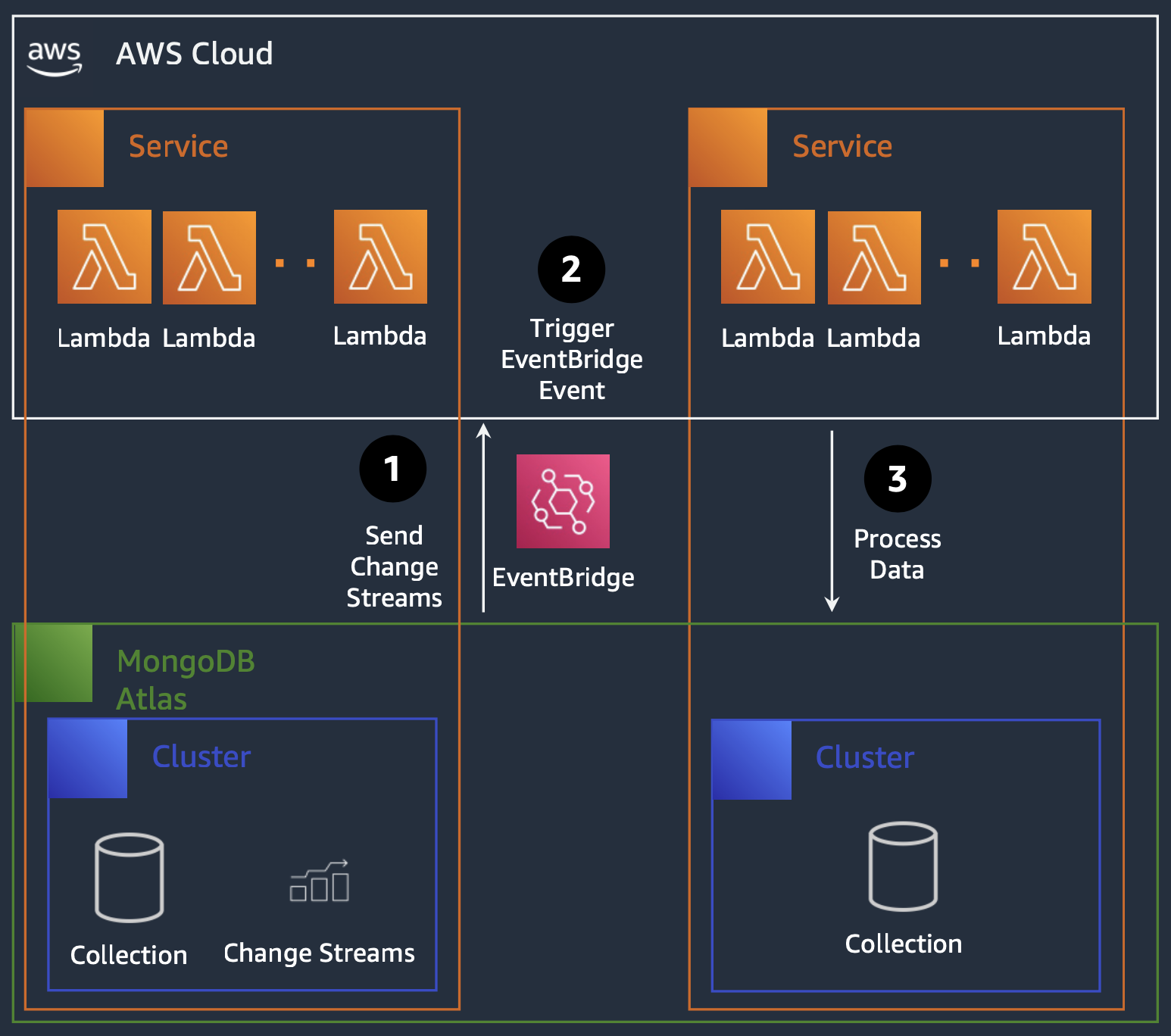
MongoDB Atlas는 MongoDB의 클라우드 기반 Managed Service로써 MongoDB를 사용하기 위한 인프라 구축에 관련된 부분을 모두 관리해주기 때문에 MongoDB Atlas를 사용하게 되었습니다. 다만 인프라 구성이 기존의 AWS VPC와 연동되지 않기 때문에 VPC Peering을 통해 연동하였습니다. 여기에 MongoDB Atlas에서는 Change Stream을 Trigger라는 이름으로 제공하고 있습니다. 이러한 Trigger에서는 MongoDB의 데이터 변화를 감지하여 이를 AWS로 보낼 수 있었는데 저희 팀에서는 이 이벤트를 EventBridge로 보내도록 처리했습니다. EventBridge는 AWS의 이벤트 버스로써 이벤트를 받아 이를 Lambda로 전달할 수 있습니다. 이를 통해 MongoDB의 데이터 변화를 실시간으로 감지하여 이를 Lambda로 전달하고 이를 기반으로 데이터들을 갱신할 수 있게 되었습니다.
4. AWS SQS 구성 (Message Queue)
기존에는 서비스 간 요청을 직접 호출하는 방식으로 진행하였습니다. 하지만 서비스 간의 직접 호출은 서비스 간의 결합도를 높이게 되고, 특정 서비스의 장애가 다른 서비스로 확산될 수 있는 결과를 가지게 됩니다. 또한 Lambda의 경우, 동시성 할당량이 제한되어 있기 때문에 데이터 연동 작업에 있어서 트래픽이 급증할 경우 Lambda의 동시성 할당량을 초과할 경우 해당 데이터들이 소실될 우려가 있었습니다. 이를 해결하기 위해 서비스 간의 통신을 Message Queue를 통해 진행하게 되었습니다. AWS에서 지원하는 Message Queue는 여러 개가 있었지만, 팀의 규모와 해당 기능의 목적성을 생각해서 크게 2가지로 선택지를 압축하였습니다.
우선 AWS MSK는 Kafka를 AWS에서 제공하는 Managed Service로써 Kafka를 사용하기 위한 인프라 구축에 관련된 부분을 모두 관리해줍니다. 다만 MSK의 경우, AWS 인프라와 연결하기 위한 작업을 수동으로 작업해야 되는 단점이 있으며 Kafka를 관리해야 하는 등의 단점이 있었습니다.
두 번째로, AWS SQS는 AWS에서 제공하는 Message Queue로써 이벤트 처리에 대한 인프라 전반에 관련된 부분을 모두 관리해줍니다. 또한, AWS Lambda와의 연동이 용이하고, Lambda의 동시성 할당량을 초과할 경우에도 데이터가 소실되지 않고 SQS에 대기하게 됩니다.
5. AWS OpenSearch 구성 (Search Engine)
기존에는 아이템 검색 기능이 별도로 존재하진 않았습니다. 하지만, 유저가 증가하고 유저들이 원하는 아이템을 손쉽게 찾기 위한 사용자 경험을 제공하기 위해 아이템 검색 기능을 추가하게 되었습니다.
이를 구현하기 위해 기존에는 MongoDB의 인덱스를 사용하여 검색 기능을 구현하고자 하였습니다. 하지만 MongoDB의 인덱스는 텍스트 검색에 최적화되어 있지 않았으며 NoSQL 특성 상 스키마가 존재하지 않는데 인덱스를 작성하게 되면 관리에 어려움이 생길 수 있기 때문에 해당 방법은 제외하였습니다.
차선책으로, AWS OpenSearch Service를 사용하고자 하였습니다. AWS OpenSearch Service는 Elasticsearch를 AWS에서 제공하는 Managed Service로써 Elasticsearch를 사용하기 위한 인프라 구축에 관련된 부분을 모두 관리해줍니다. 또한, Elasticsearch의 경우, 텍스트 검색에 최적화되어 있기 때문에 MongoDB의 인덱스를 사용하는 것에 비해 더 풍부한 기능을 활용할 수 있었습니다.
6. AWS S3 + Athena 구성 (Logging)
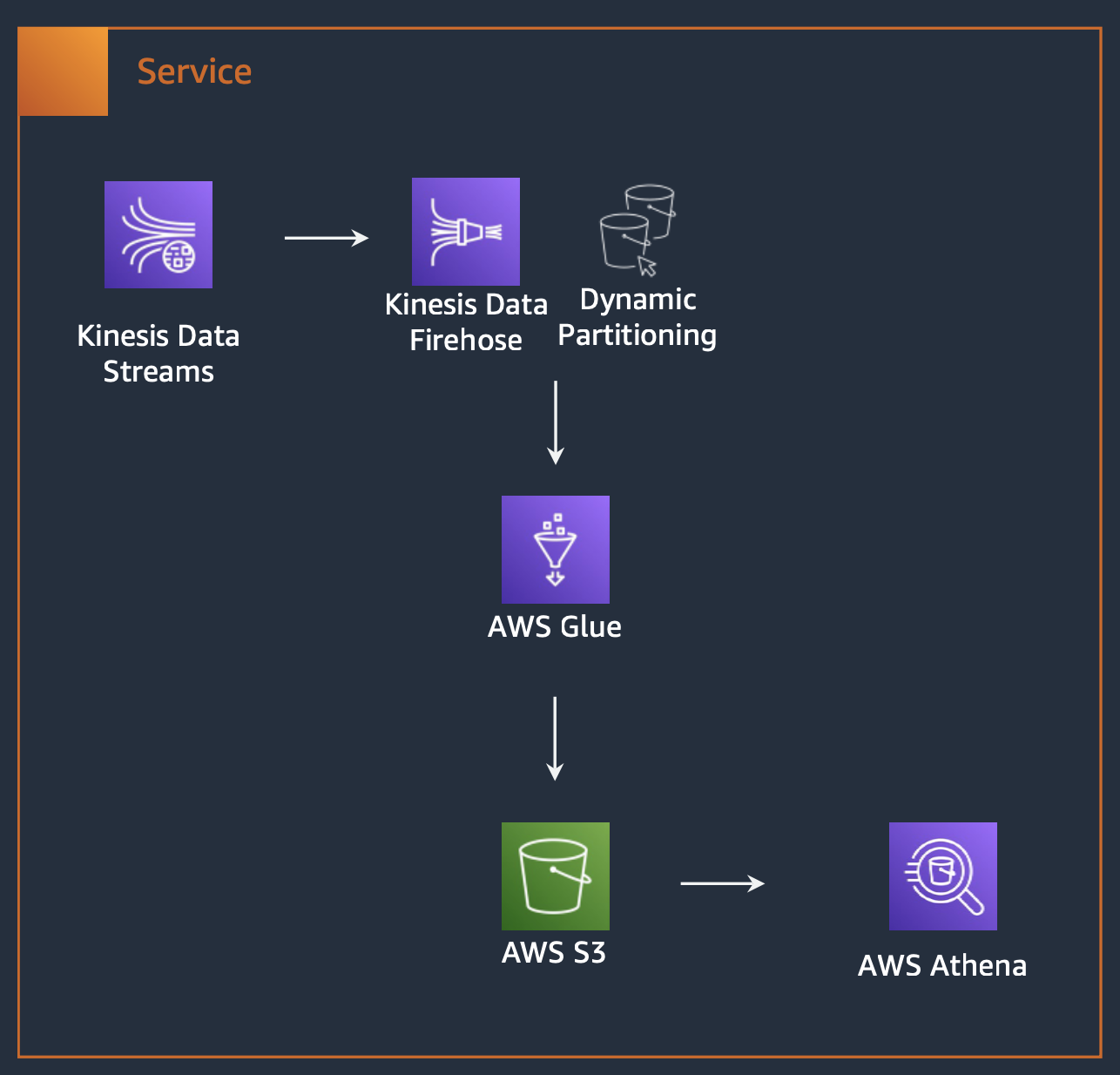
이를 구현하기 위해 기존에는 MongoDB의 로그를 사용하고자 하였습니다. 하지만, MongoDB의 로그는 텍스트 형식으로 저장되어 있기 때문에 로그를 분석하기 위해서는 별도의 로그 분석 툴이 필요하고, 로그를 분석하기 위한 쿼리를 작성해야 하는 등의 단점이 있었습니다.
다른 방법을 모색한 결과, AWS S3와 Athena를 사용하고자 하였습니다. AWS S3는 AWS에서 제공하는 Object Storage로써 로그를 저장하기 위한 파일들을 AWS에서 관리할 수 있습니다. 또한, AWS S3에 저장된 로그를 Athena를 통해 쿼리를 작성하여 로그를 분석할 수 있습니다.
이러한 로깅 시스템을 구축하기 위해 AWS Kinesis를 도입했습니다. AWS Kinesis는 AWS에서 제공하는 Streaming Data Service로써 로그를 수집하기 위한 데이터 파이프라인 인프라에 대한 관리형 서비스를 제공합니다. Kinesis를 통해 축적된 로그 데이터는 Firehose를 통해 S3에 저장되고, 이를 Athena를 통해 쿼리를 작성하여 로그를 분석할 수 있게 됩니다. 또한, Athena 쿼리 분석 속도 향상을 위해 AWS Lambda를 활용하여 파티셔닝을 진행하였습니다.
7. Datadog 구성 (Monitoring)
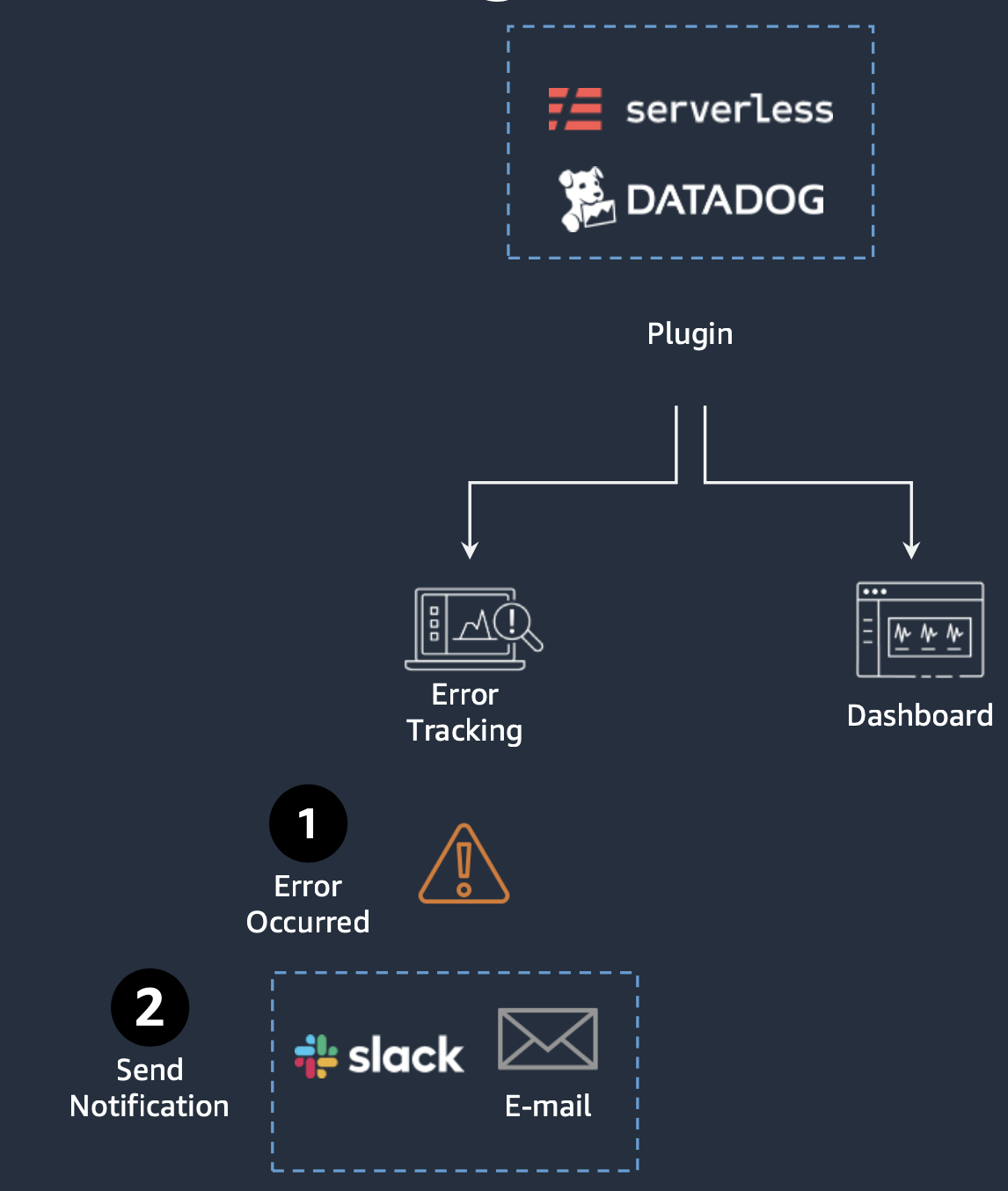
이를 해결하기 위해 기존에는 AWS CloudWatch를 사용하고자 하였습니다. 하지만, CloudWatch가 제공하는 기능들 만으로는 에러 로그를 수집하고, 이를 통해 서비스의 상태를 파악하기에는 한계가 있었습니다. 이에 다른 팀에서 활용 중인 Datadog를 도입하여 서비스 모니터링을 구성하였습니다.
AWS 계정 연결을 통해 인프라에서 사용중인 전반적인 리소스들의 상태를 모니터링할 수 있었고, 서비스에서 발생하는 에러 로그를 수집할 수 있게 되었습니다.
MSA 구성상 발생한 문제점
1. 인프라 구성의 복잡성
기존에는 AWS 상의 인프라가 비교적 간단하기 때문에 수동으로 관리하는 것이 가능했습니다. 하지만 MSA로 변경되면서 인프라가 복잡해지고 이를 관리하기 위해서 AWS CloudFormation과 같은 IaC 도구를 사용하게 되었습니다. 이를 통해 대부분의 AWS 기능들은 CloudFormation을 통해 관리하게 되었지만, MongoDB Atlas와 같은 AWS가 아닌 외부 서비스들은 CloudFormation을 통해 관리할 수 없었습니다.
따라서 MongoDB와 같은 외부 서비스들은 기존에는 수동으로 관리하였습니다. 하지만 stage에 따른 인프라 구성 변경을 수동으로 관리하기에는 개발자들이 휴먼 에러를 일으키기 쉬운 환경이었기에 다른 방법을 찾고자 하였습니다.
MongoDB Atlas에서는 이러한 MongoDB 인프라 구성을 관리하기 위한 CLI 도구로써 Realm CLI를 제공하고 있었습니다. 이러한 Realm CLI를 통해 인프라 관리를 커맨드라인에서 진행할 수 있게 되었습니다. 하지만 이러한 관리 방식의 파편화는 인프라 관리에 있어서 부담을 가지게 되었습니다.
여기에 한번은 Trigger 서비스에서 장애가 발생한 적이 있어서 Change Data가 누락된 적이 있었는데, 인프라가 분리되어 있다보니 이러한 데이터 연동 누락의 확인이 늦어지게 되었습니다. 또한 해당 서비스의 복구까지 시간이 소요되었고 이 기간 동안 데이터 연동이 누락되었기 때문에 수동으로 연동을 수행한 경험이 있었습니다. 인프라가 분리되어 있기 때문에 이러한 관리 포인트의 누락은 향후 서비스에도 큰 문제가 될 수 있는 부분이었습니다.
2. 인프라 구성의 비용
MongoDB Atlas에서는 MongoDB 인프라 구성을 위한 관리형 인스턴스를 제공하고 있었습니다. 이러한 인스턴스는 MongoDB Atlas에서 관리하기 때문에 MongoDB를 활용하기 위해서는 MongoDB Atlas의 인스턴스 비용을 추가로 지불해야 했습니다.
마이크로서비스 별로 데이터베이스가 분리되는 만큼 인스턴스 비용이 추가로 발생하게 되었습니다. 게다가 개발 진행 당시에는 Serverless 형식의 서비스가 Preview 형태로 제공되어 있어 비용적으로는 효율적 일지라도 안정성의 이슈가 있었습니다.
결론. AWS DynamoDB 도입
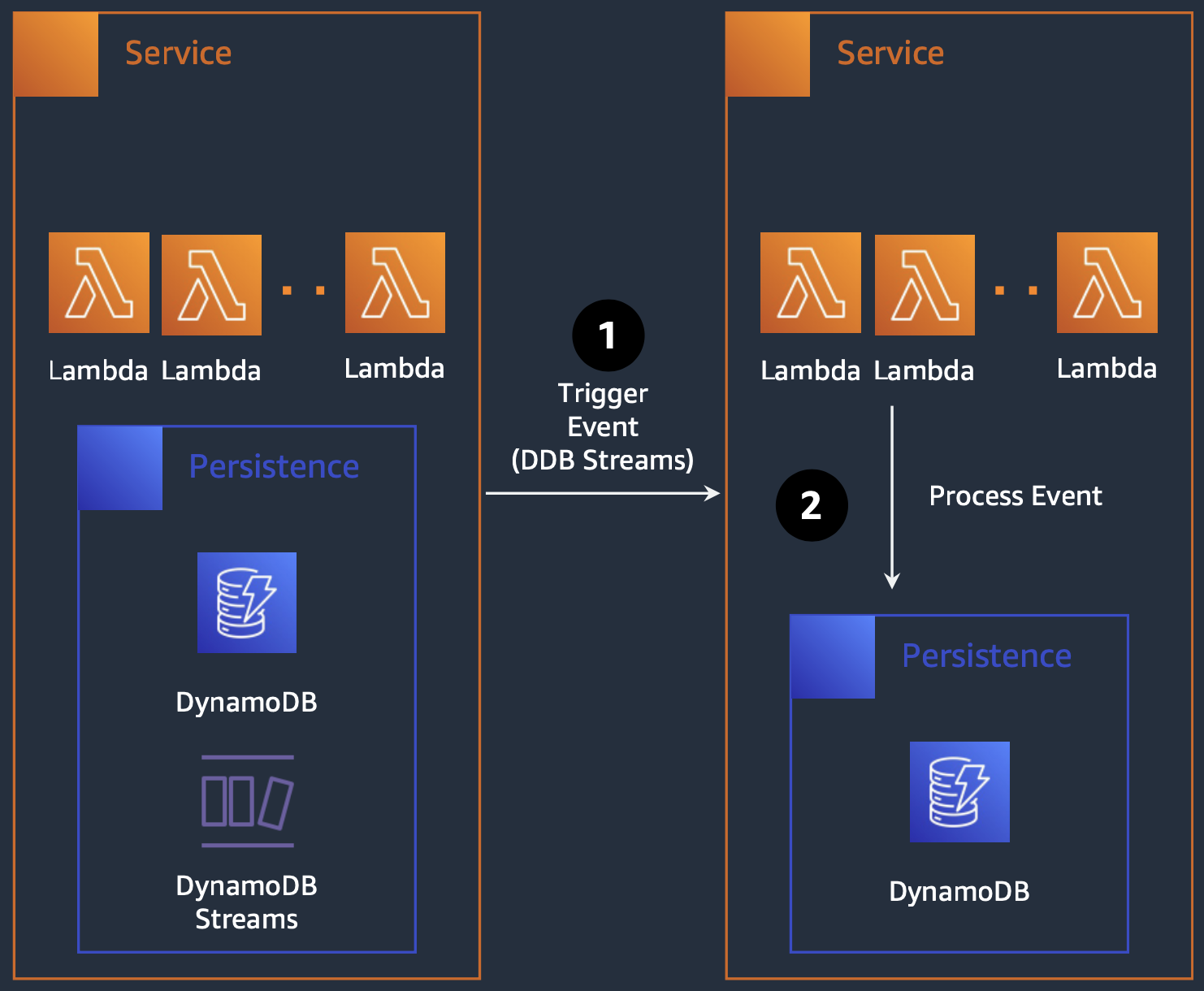
AWS DynamoDB는 MongoDB Atlas와 달리 AWS에서 제공하는 서비스이기 때문에 AWS CloudFormation을 통해 관리할 수 있었습니다. 이를 통해 GSIs(Global Secondary Index)로 관리할 수 있었고, 이를 통해 데이터를 더욱 효율적으로 관리할 수 있었습니다. 다만, CloudFormation을 통해 GSI를 관리할 때 하나의 테이블에서 한번에 하나의 GSI만 수정/삭제가 가능했기 때문에 이부분을 주의하며 개발을 진행했습니다.
또한 기존에는 캐싱 서비스를 구축하지 않아 DB로의 부하가 직접적으로 노출되었으나 DynamoDB에서는 DAX라는 캐싱 서비스를 제공하고 있었습니다. 캐싱을 활용하여 DB로의 부하를 줄일 수 있었고, 이를 통해 트래픽 증가에 따른 인프라 관리 부담을 줄일 수 있었습니다.
추가 고려 사항
1. AWS Lambda의 Cold Start
AWS Lambda는 서버리스 아키텍처로써 서버를 관리할 필요가 없이 서비스를 수행할 수 있습니다. 다만 서버가 없기 때문에 서비스가 최초로 호출될 때 서버를 생성하는 과정이 필요합니다. 이를 Cold Start라고 하는데, 이 과정에서 시간이 소요되기 때문에 이를 최소화하기 위한 방법을 고려해야 합니다.
이를 위해 다양한 방법이 존재하는데, 가장 간단한 방법은 Lambda 함수를 미리 호출하는 것입니다. 일반적으로 Lambda 함수는 최초 호출 시 Cold Start가 발생하고 이후 15분 동안에는 Warm Start가 발생합니다.
이를 활용하여 Lambda 함수를 미리 호출하면 Cold Start가 발생하지 않고 Warm Start가 발생하게 됩니다. 하지만 이를 위해 별도의 서비스를 구축하는 것은 개발자들이 관리적인 측면에서 인프라를 위한 인프라 구축을 하기 때문에 배제하게 되었습니다.
두번째 방법으로, Provisioned Concurrency를 활용하는 방법이 있습니다. 이는 AWS에서 제공하는 방법으로 Lambda 함수를 미리 호출하는 것과 유사한 방식으로 동작합니다. 실제로 인스턴스들을 지정된 갯수만큼 인스턴스를 미리 생성하게 됨으로써 해당 동시성만큼의 Lambda 함수들은 Cold Start가 발생하지 않게 됩니다. 하지만, 이는 인스턴스를 미리 생성하기 때문에 비용적인 측면에서는 비효율적이라는 단점이 있었으며, 해당 동시성 이상의 호출이 발생할 경우 마찬가지로 Cold Start가 발생하기 때문에 현재 리전의 최대 동시성과 동접 인원에 맞춘 동시성 제공을 통한 비용 효율화가 수행되어야 합니다.
2. RDS 구성 (Relational Database)
기존에는 주요 서비스들이 서비스 외부에서 동작하기 때문에 NoSQL만 사용하고도 모든 기능을 수행할 수 있었습니다. 하지만 플랫폼에 다양한 기능이 추가되면서 NoSQL만으로는 데이터 정합성 체크가 어렵게 되었습니다.
AWS DynamoDB의 경우 Eventually Consistency를 제공하기 때문에 데이터 정합성 체크가 어려웠습니다. 데이터 갱신이 리전에 전파됨에 있어서 250ms 가량의 딜레이가 있으며 Primary Key나 LSIs(Local Secondary Index)를 통한 데이터 조회의 경우 이를 보장할 수 있지만, GSI의 경우 DynamoDB에서 Strong Consistency를 보장하지 않습니다.
글로벌 보조 인덱스 또는 DynamoDB 스트림에서의 강력히 일관된 읽기는 지원되지 않습니다.
참고. DynamoDB 읽기 정합성
따라서 데이터 정합성 체크를 위해서는 DynamoDB Streams를 활용하여 데이터 변경 이벤트를 통한 갱신 처리를 수행하게 되었습니다. 하지만 이는 데이터 갱신 이벤트를 통해 데이터를 갱신하기 때문에 갱신 속도에 지연이 발생함에 따라 TPS가 낮아지게 됩니다. 또한, 이를 위해 별도의 인프라를 구축해야 하고 동시 데이터 갱신 시 실패 처리 등에 대한 로직을 추가로 작성해야 했습니다.
이러한 복잡성 때문에 데이터 정합성 체크를 위해 RDB를 사용하는 것이 근본적인 해결책임을 알게 되었으나 개발 일정 상 해당 이슈는 TPS를 희생하는 것으로 넘어가게 되었습니다.
마무리
기존의 monolithic 구조에서 MSA로 점진적으로 변경하면서 구조 설명과 이를 위한 인프라 구성에 대해 알아보았습니다. 비록 전환 과정이 무조건적인 이득만 있는 부분이 아닌만큼 각 서비스의 특성과 개발 리소스에 따라 적절한 수준의 아키텍쳐를 구성하는 것이 중요한 점을 느낄 수 있었습니다.
참고