- Published on
es6-babel-webpack
- Authors

- Name
- Hoehyeon Jung
모던 자바스크립트란?
자바 스크립트는 ES2015 스펙 발표 이후로 급격하게 많은 것들이 추가되고 발전하게 되었다. 이제 변수는 블록 스코프 단위로 선언되며 호출될 것이며, 기존 함수 선언을 람다 표현식으로 바꿔 간결하게 표현할 수 있는 화살표 함수가 등장했다. 다른 언어에서 OOP 개발을 위해 사용되었던 class가 도입되었으며, 전역 네임스페이스 오염 방지하고 모듈 내부의 독립된 스코프를 보장하는 모듈 시스템의 도입, 비동기 콜백 함수의 콜백 지옥에서 벗어나게 해준 Promise도 있으며, ES5 이전 라이브러리와의 property 중복으로 인한 문제 해결을 위해 등장한 새로운 타입인 Symbol도 있다. 여기서 끝이 아니다. 반복을 좀 더 우아하게 처리해 줄 수있는 이터레이터/이터러블 프로토콜의 적립과 이터레이터/이터러블 프로토콜을 만족하며 제어권을 넘겨주는 코루틴적인 특성을 가진 제네레이터, 비동기 동작을 동기처럼 수행하게 도와주는 await/async 등 기존에 없던 새로운 문법이 등장했다. 비록 제네레이터나 await/async 문법은 ES2015 이후에 적립되었지만 그 전에 있는 것들은 모두 ES2015에서 정의된 스펙이다. 매년 TC39팀에서는 자바스크립트 스펙을 정의하여 발표하는 데, ES2015를 기준으로 다양한 기능을 추가하였기 때문에 이 시점을 기준으로 모던 자바스크립트라고 불리게 된다.
같은 코드가 항상 같은 결과를 보여주진 않는다.
모던 자바스크립트의 등장은 모던이라는 수식어가 붙을만큼 자바스크립트를 더 우아하게 만드는 많은 변화가 있었다. 하지만, 이러한 스펙 발표와는 별개로 각각의 브라우저에서 해당 문법을 사용하기 위해서는 브라우저 개발자 측에서 해당 스펙을 구현해야 한다. 하지만, 각 브라우저 개발사마다 저마다의 개발 우선 순위가 있기도 하고 기반이 되는 브라우저 동작 방식도 다르는 등 해당 스펙을 구현하는 방식이 제각각 다를 수 밖에 없다. 물론 이러한 스펙들을 훌륭하게 구현하는 브라우저도 있는 반면, 개발 지원 중단 등의 이유로 JS 스펙의 구현 등이 중단된 브라우저도 있다.
따라서, 이러한 브라우저 간 호환성을 만족시켜주면서 기존 JS 바닐라 코드들을 간결하게 추상화한 jQuery가 엄청난 유행을 끌기도 했다. 이렇듯, 모든 브라우저에서 같은 코드가 동일한 기능으로 동작하게 하는 것은 개발자들의 가장 큰 고민거리 중 하나였다. 모던 자바스크립트 개발 환경에서는 이러한 호환성을 전문적으로 관리해주는 도구가 생겼다. 이러한 도구들의 등장으로 인해 이제는 해당 코드가 특정 브라우저에서 구현되지 않았다고 해도 이를 감지하고 변환해준다. 이러한 기능을 트랜스파일(transpile)이라고 하며 브라우저 간의 호환이나 구현되지 않은 함수를 구현하는 등의 기능을 수행한다.
Transpile vs Compile 트랜스파일(transpile): 비슷한 수준의 추상화를 가진 다른 언어로 변경 (ES6 => ES5, C++ => C) 컴파일(Compile): 서로 다른 수준의 언어로 변경 (JAVA => Bytecode, C => Assembly, Dart => Javascript)
책임은 늘어나도 언제나 빨라야 한다.
구글의 V8 엔진으로 인해 자바스크립트의 속도가 비약적으로 빨라졌고, ES2015의 등장으로 좀 더 세련되면서 모던한 자바스크립트의 개발이 가능하게 되었다. 또한 Node.JS의 등장으로 자바스크립트는 브라우저 밖에서도 눈부신 활약을 할 토대를 얻게 되었다. 또한 자바스크립트는 현재 세계에서 가장 거대한 오픈소스 라이브러리 저장소 NPM을 통해 바퀴를 재창조하지 않고도 어플리케이션을 조립해서 완성할 수 있게 되었다. 이러한 순풍들을 타고 자바스크립트는 기존의 DOM 조작을 넘어서 훨씬 더 많은 일들을 수행하게 되었다. 페이지의 한계에서 어플리케이션으로 확대된 자바스크립트는 필연적으로 더 무거워지고 레거시 코드들의 파편화 등의 문제를 끌어앉게 되었다. 비즈니스 로직 수행을 위해 여러 개의 모듈을 불러와 페이지를 구현할 경우 HTTP 특성 상 파일이 많아지면 초기 로딩이 지연되기도 하고, 특정 기능을 수행하기 위해 특정 모듈을 이용해 기능을 구현하였다가 이후 기능 수정으로 해당 함수를 사용하지 않더라도 해당 함수의 사이드 이펙트 등의 문제로 쉽사리 제거하지 못하고 파편화되기도 한다. 이러한 문제점들로 인해 브라우저가 느려진다면 우리는 더 복잡하고 느린 아키텍처를 도입할 이유가 사라질 것이다. 다행스럽게도 이러한 문제점을 해결하기 위한 도구 역시 존재한다. 각 모듈들의 의존관리를 분석하고 이를 하나의 파일로 묶어주는 번들링(Bundling) 역할을 수행함으로 인해 개발자는 각 모듈들을 최소한의 책임을 가지도록 충분히 작게 만들더라도 번들링으로 파일들을 묶어줄 수 있다.
그래서 그것들이 대체 뭔가요?
모던 자바스크립트 개발 환경에서 빠질 수 없는 두 축으로 앞에서 언급된 바와 같이 트랜스파일러(Transpiler)와 번들러(Bundler)가 있다. 먼저 트랜스파일러부터 살펴보자면 바닐라 JS 에서 가장 많이 쓰이는 Babel과 타입 추론과 제네릭 등의 강력한 타입 체킹 시스템이 있는Typescript(Compiler)가 있다. 모듈러를 살펴보면, 가장 많이 쓰이는 Webpack과 Zero Config를 표방하여 등장했던(Webpack도 4버전 이후부터는 Zero Config 지향), ES Module 형식을 지원하는 Rollup 등이 있다. 우리는 이중에서 각각 Babel과 Webpack을 통해 트랜스파일러와 번들러의 원리를 이해하고자 한다.
Babel
The Compiler for writing next generation Javascript
위에도 써있듯이 바벨은 개발자가 최신의 자바스크립트를 쓸 수 있도록 도와주는 컴파일러라고 소개하고 있다. 바벨은 이와 같이 아직 도입되지 않은 (stage 0 ~ 3) 기능들을 사용하게 할 수 있다. 그렇다면 바벨은 어떻게 코드를 컴파일하는 것일까?
AST (Abstract Syntax Tree)
미리 답을 말하자면 코드를 분석해서 AST를 만들고 이를 이용해서 처리한다. 이는 우리가 아는 일반적인 컴파일러들이 수행하는 동작이다. 그럼 그 중에서 AST를 만드는 과정에 대해 알아보자. 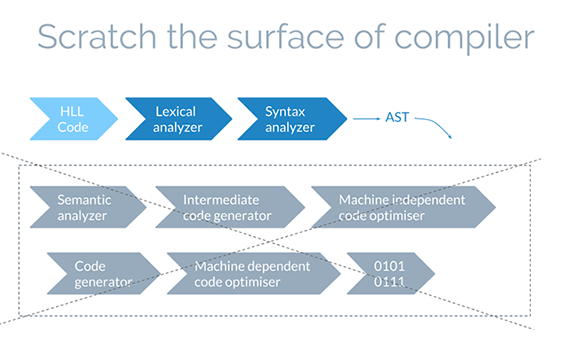 [출처: https://gyujincho.github.io/2018-06-19/AST-for-JS-devlopers]
[출처: https://gyujincho.github.io/2018-06-19/AST-for-JS-devlopers]
컴파일러에서 AST를 만드는 과정만을 살펴보자. 고차 언어로부터 Lexical analyzer, Syntax analyzer를 거쳐 AST가 나오는 것을 알 수 있다.
Lexical analyzer (scanner)
스캐너라고 불리는 어휘 분석기는 코드를 읽어들여 정의된 규칙에 따라 문자 스트림(코드)를 읽고 이를 토큰으로 결합한다.
const a = 5;
// [{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...]
Syntax analyzer (parser)
파서라고 불리는 구문 분석기는 어휘 분석기를 통해 변환된 플랫한 토큰으로부터 검증 과정을 거친 후, (에러가 있으면 에러를 표시해주는) AST를 만든다.
const a = 5;
{
"type": "VariableDeclaration",
"declarations": [{
"type": "VariableDeclarator",
"kind": "const",
"id": {
"type": "identifier",
"name": "a"
},
"init": {
"type": "literal",
"value": 5
}
}]
}
컴파일러에서 AST로 생성하는 구조는 대략적으로 위와 같다. 이를 개념적으로만 접근해보기보다는 실제 활용 예제를 알아보자.
@Babel/parser
과거 babylon으로 불리었지만 babel v7에 들어서면서 완전히 포함되어 @babel/parser가 되었다. babel의 하위 프로젝트인 만큼 강력한 지원을 받고 있는 만큼 대부분의 최신 문법을 지원할 것이다.
다시 돌아와서 Babel
그렇다면 Babel은 어떻게 동작하는 걸까? AST로 변환된 정보가 어떻게 코드를 변환하는 걸까? babel은 3가지 단계를 통해 코드를 source-to-source compile(transpile)을 수행한다. 각각 parse, transform, generate 단계를 거치게 된다. 여기서 각 단계 별로 AST 트리를 생성하고, 적용된 플러그인에 따라 AST를 수정하고, 최종적으로 AST에서 코드를 생성하는 과정을 수행한다.
// parse
import * as parser from '@babel/parser';
const code = `
const abc = 5;
`
const ast = parser.parse(code);
// transform
import traverse from '@babel/traverse';
traverse(ast, {
enter(path) {
if (path.node.type === 'Identifier') {
path.node.name = name.split('').reverse().join('');
}
}
});
import generate from '@babel/generator';
const newCode = generate(ast); // const cba = 5;
위 과정에서 가장 눈여겨 살펴보아야 할 곳은 transform에 해당되는 부분이다. parsing하여 AST로 만들거나, transform을 통해 원래 코드로 작성하는 것은 일련의 규칙을 통해 이루어진다. 하지만 AST 트리를 적절하게 변환하는 것이 ES2015+ 코드를 ES5로 바꿔 호환성을 챙기거나 하는 등의 핵심적인 기능을 수행하는 것이다.
따라서, Babel 플러그인을 작성하는 것은 transform에 해당되는 부분을 작성하는 것이다. 플러그인은 따라서, Babel 플러그인을 작성하는 것은 transform에 해당되는 부분을 작성하는 것이다. Babel 플러그인은 visitor라는 노드를 순회하며 선언된 부분을 변경하는 함수를 작성만 하면 된다.
// my-babel-plugin.js
export default function () {
return {
visitor: {
Identifier(path) {
const name = path.node.name;
path.node.name = name.split('').reverse().join('');
}
}
}
}
트랜스파일러의 역할
코드를 분석하여 변환할 수 있는 강력한 기능은 단순히 ES2015+의 코드를 변환해주는 데에 그치는 것이 아니라, 공백이나 불필요한 option token들을 제거해주는 코드 압축(minification) 기능을 수행할 수 있다. 또한, JSX를 변환하거나 Flow와 같은 언어를 위한 플러그인으로도 쓰일 수 있는 등 코드 변환에 필요한 다양한 기능을 수행할 수 있다.
참고(출처)
- minification: 공백이나 불필요한 옵션을 제거하는 것.
- uglification: 길이가 긴 변수나 함수, 메서드명 등을 압축하는 것으로 이에 따라서 읽기 어려운 형태로 코드가 변하고 되돌릴 수 없다(irreversible).
polyfill로써의 Babel
코드를 변환하는 것으로 모든 문제를 해결할 수 있으면 좋겠지만 ES2015 이후에 새로 생긴 메서드나 Symbol같은 자료형은 코드 변환만으로 해결할 수 없다. 이렇게 없는 메서드들을 이전의 존재하는 메서드 등으로 해결하는 플러그인도 제공한다. 해당 플러그인을 프로젝트 루트 파일에 한번 import 해주면 된다.
Webpack
현대의 Javascript 어플리케이션은 크기도 거대해지고 기능에 따라 분화된 작은 javascript 코드들이 서로 어우러져 동작한다. 이러한 거대해진 용량의 파일들을 불러와서 파싱을 수행하고 컴파일되어 최종적으로 실행되기까지 페이지를 작성하기까지의 공백은 이전보다 더 길어지게 되었다. 이는 지극히 자연스럽고 효율적인 변화지만 실제 사용자에게 이러한 파일 구조의 파일들을 그대로 제공하는 것은 부적절하다. 파일이 여러 개라는 것은 하나의 웹 어플리케이션을 동작하기 위해 적게는 수십, 수백개의 파일들을 네트워크를 통해 불러오거 되고 이는 병목 현상에 의한 지연 시간이 발생하고 이것이 충분히 길어지면 사용자 경험에도 악영향을 준다. 이를 해결해주는 Bundling, 즉 여러 개의 자바스크립트 파일들을 하나의 파일로 묶어주면서 동시에 각 모듈 파일들 간의 이름 충돌 등의 문제도 해결해준다.
Webpack이 동작하는 방식
Webpack은 어떻게 파일을 모아서 bundling을 수행할까? Webpack은 dependency graph을 생성해서 자바스크립트 파일 간의 의존성을 그린다. 이를 통해 중복이 발생하지 않는 최소 단위인 chunk를 만들고 이러한 chunk들이 모여서 하나의 bundle이 되는데 이것을 Webpack이 수행한다. Webpack은 여러 개의 모듈을 chunk로 결합하면서도 어떻게 변수명의 충돌 등을 해결할 수 있었을까? Webpack에서는 각각의 모듈을 IIFE를 활용하여 변수 스코프 문제를 해결하였다. IIFE를 통해 각 모듈내 변수들은 해당 IIFE 내부의 스코프에서만 동작하는 점을 이용한 것이다. 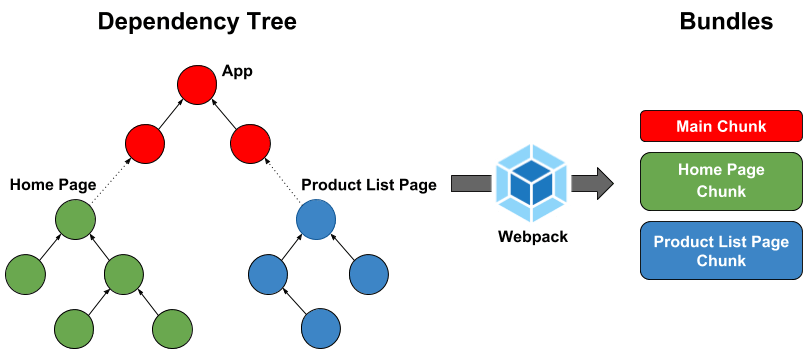 buldle and chuck
buldle and chuck
Show me the code
Webpack도 Babel과 유사하게 핵심적인 부분들이 여러 개로 나뉘어져 구성되어 있다. 이 요소들을 설정 파일을 통해 하나씩 살펴보자.
entry
- dependency grap를 만들기 위한
Input Source이다. - 직,간접적으로 의존성을 파악하고 있다.
- 여러 개가 존재할 수 있다.
output
- Webpack으로 인해 번들링된 결과물이 저장될 위치를 지정한다.
const path = require('path');
module.exports = {
entry: './path/to/my/entry/file.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'my-first-webpack.bundle.js'
}
};
Loader
- Webpack은 기본적으로 javascript와 json 파일만을 이해할 수 있다.
- loader를 통해 다른 종류의 파일들을 webpack이 이해할 수 있도록 변경한다.
plugin
- bundle optimization, asset management, injection of environment 등의 기능을 수행한다.
const HtmlWebpackPlugin = require('html-webpack-plugin');
const webpack = require('webpack');
module.exports = {
module: {
rules: [
{ test: /\.txt$/, use: 'raw-loader' }
]
},
plugins: [
new HtmlWebpackPlugin({template: './src/index.html'})
]
};
mode
- Webpack이 빌드되는 Profile을 지정한다.
- development, production, none
최적화를 위한 또다른 기술
Webpack은 Bundling 이외에도 빌드 파일 최적화를 위한 기술들을 가지고 있다. 바로 Code Splitting과 Tree shaking이다.
Code Spliting
Webpack을 통해 Bundling을 수행하게 되면 어플리케이션이 발전함에 따라 필연적으로 용량이 증가하게 된다. 이러한 거대한 용량의 파일을 한꺼번에 불러오는 것이 병목현상의 원인이 되는 것이다. Code Splitting이란, 이러한 한 뭉치의 코드에서 지연 로딩을 통해 필요한 요소들만 필요할 때 로딩 함으로써 한꺼번에 큰 용량의 파일을 호출하는 것을 방지하는 것이다. 지연 로딩을 구현하기 위해서 동적 import를 이용하는 방법이 있다.
import React, { Component } from 'react';
class App extends Component {
handleClick = () => {
import('./notify').then(({ default: notify }) => {
notify();
});
};
render() {
return (
<div>
<button onClick={this.handleClick}>Click Me</button>
</div>
);
}
}
export default App;
Tree shaking
우리가 특정 모듈에서 유용한 함수를 불러오기 위해서 해당 모듈을 import한다. 하지만 해당 모듈의 전체 기능을 모두 사용하지 않는 경우가 대부분이기 때문에 전체 모듈을 불러오는 방식은 비효율적이다. 따라서 우리는 import와 Destructing Object를 통해 해당 모듈에서 필요한 파일들만 불러온다. 그렇다면 실제로 Bundling이 진행될 때도 해당 모듈에서 필요한 파일만 가져와서 용량을 줄일까? 그럴 수도 있고 아닐 수도 있다. Webpack이 기본적으로 tree shaking을 통해 import되는 모듈들을 다이어트 시켜주긴 하지만, 어디까지나 ES module에 한정된 이야기이다. CommonJS 형식의 모듈을 tree shaking이 진행되지 않기 때문에 별로의 plugin을 이용하거나 es module로 제작성된 모듈을 이용하거나 혹은 파일 디렉토리 구조를 통해 나눠진 모듈에서 필요한 부분만 가져오는 chery picking 방식을 이용하여야 한다.
// 설정이 잘 되어있어도 lodash 모든 것들을 가져온다.
import { sortBy } from "lodash";
// sortBy 경로에서 가져온다.
import sortBy from "lodash-es/sortBy";
HTTP/2의 등장
TCP를 기반으로 작성된 HTTP 프로토콜은 시간이 지나면서 꾸준히 발전하였다. 전송 속도를 빠르게 하기 위해 Header 구조를 개선하고 반복되는 Handshaking으로 인한 지연을 방지하기 위해 커넥션을 재사용하도록 하기도 했다. 게다가 HTTP/2에 들어서면서 Multiplexed Streams를 통해 동시에 여러 요청을 수행할 수 있게 되었다. 한꺼번에 여러 요청을 수행할 수 있다는 것은 여러 개의 자원이 전송될 때의 RTT(Round Trip Time)도 같이 감소한다는 것을 의미한다. 그렇다면 HTTP/2를 도입한 백엔드/프론트엔드 환경에서는 Bundling의 이점이 크게 줄어들게 되고 Webpack을 사용할 필요성이 없어지지 않을까?
그렇게 됐으면 (개발자) 모두가 좋겠지만, 아쉽게도 개선된 프로토콜만으로 네트워크 병목을 완전히 해결하긴 힘들다.
다음의 article들을 살펴보고 해당 결과를 요약하면 다음과 같다.
http://engineering.khanacademy.org/posts/js-packaging-http2.htm https://medium.com/@asyncmax/the-right-way-to-bundle-your-assets-for-faster-sites-over-http-2-437c37efe3ff
- 아직 각각의 작은 파일들의
protocol overhead가 하나의 큰 파일에 비해 여전히 존재한다. - 단일 파일의 압축(compression)이 여러 파일들보다 낫다.
서버는 여러 개의 작은 파일을 보내는 것이 하나의 큰 파일을 보내는 것보다 느리다.
하지만 chunk의 크기가 줄고 갯수가 늘어나는 것은 caching의 관점에서는 충분히 이득이다. 작은 변화에도 하나의 큰 파일이 변경되는 것이랑 작은 파일 몇 개가 수정되는 것은 분명히 차이가 존재한다. 그렇다면 우리는 그 중간점인 Sweet spot을 어떻게 찾아서 Bundling 할 수 있을까?
Webpack에서는 다행이도 HTTP/2 프로토콜을 위한 plugin을 제공하고 있다. Webpack의 AggressiveSplittingPlugin은 하나의 이전의 chunk 파일들을 더 작은 범위로 분할한다. 개발자가 이 값을 직접 지정할 수도 있기도 하다.
마치며
프론트엔드 개발을 실무로 직접 뛰면서 모던 JS 개발환경을 몸소 느끼다보니 욕심을 가지고 이것 저것 여러 개의 주제를 참고해서 글을 작성하였지만, 작성자의 짧은 식견으로 인해 각 part들의 깊이가 다소 얕은 감이 있다. 당장 1년 뒤에 내가 이 글을 돌아보며 이불을 뻥뻥 찰 수 있게 앞으로도 더 열심히 JS 및 프론트엔드 개발에 노력해야겠다.
참고